Troubleshooting¶
Calibration (correct or dark) request failed:¶
- Check if there is an available PDF report.
- In case report exists, open it and check what kind of error is available in the PDF report.
- There is no available report, next step would be checking the logs for the calibration webservice. The webservice can be accessed with the access to maxwell cluster.

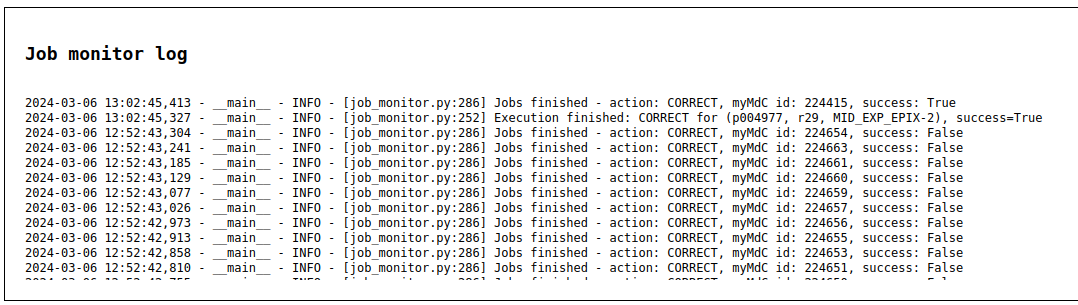
Processing failed and report mentions no trains to process.¶
- Validate the raw data by checking the number of available trains.
h5glancecan be a useful tool for this purpose.- Check if the output shows a shape of (0, ...) for the datasets in detector INSTRUMENTS data group.
Processing failed and report shows an error¶
- Validate the raw data and that it has no unexpected datasets or train mismatches.
extra-data-validatecan be a useful tool for doing this.- In case data was not validated report the issue to the DOC and mention the reason for the failed validation.
- In case the data was validated, report the issue to CAL to investigate.
Slow calibration processing¶
It can happen that an instrument reports an un usual slowness in processing. It is essential to differentiate between slowness in processing the data after the request was directly triggered or if the instrument are receiving a report too late after myMDC should have triggered a calibration.
This is important because there can be different issues that will need different groups to follow up on.
Data migration takes too long¶
- The calibration webservice obviously shouldn't start any calibration until the data has been migrated from
ONCto/gpfs/.
In multiple instances there were migration issues, either because of a pileup because of how often small runs are acquired and migrated in a proposal or because of a specific issue that ITDM needs to investigate.
To confirm that the slowness in calibration is related to slow migration, one can check the calibration webservice log through the webservice overview webpage or if you have access to xcal@max-exfl-cal001.desy.de to check the log files in the running deployed pycalibration instance. Below is an example of logs showing many tries for the webservice to check if data was migrated for run 22 to start offline correction.
2023-06-07 12:16:00,161 - root - INFO - [webservice.py:351] python -m xfel_calibrate.calibrate agipd CORRECT --slurm-scheduling 1568 --slurm-partition upex-middle --slurm-mem 700 --request-time 2023-06-07T12:13:38 --slurm-name correct_MID_agipd_202301_p003493_r22 --report-to /gpfs/exfel/exp/MID/202301/p003493/usr/Reports/r22/MID_DET_AGIPD1M-1_correct_003493_r22_230607_121600 --cal-db-timeout 300000 --cal-db-interface tcp://max-exfl016:8015#8044 --ctrl-source-template {}/MDL/FPGA_COMP --karabo-da AGIPD00 AGIPD01 AGIPD02 AGIPD03 AGIPD04 AGIPD05 AGIPD06 AGIPD07 AGIPD08 AGIPD09 AGIPD10 AGIPD11 AGIPD12 AGIPD13 AGIPD14 AGIPD15 --karabo-id-control MID_EXP_AGIPD1M1 --receiver-template {}CH0 --compress-fields gain mask data --recast-image-data int16 --round-photons --use-litframe-finder auto --use-super-selection final --use-xgm-device SA2_XTD1_XGM/XGM/DOOCS --adjust-mg-baseline --bias-voltage 300 --blc-set-min --blc-stripes --cm-dark-fraction 0.15 --cm-dark-range -30 30 --cm-n-itr 4 --common-mode --ff-gain 1.0 --force-hg-if-below --force-mg-if-below --hg-hard-threshold 1000 --low-medium-gap --mg-hard-threshold 1000 --overwrite --rel-gain --sequences-per-node 1 --slopes-ff-from-files --xray-gain --max-tasks-per-worker 1 --in-folder /gpfs/exfel/exp/MID/202301/p003493/raw --out-folder /gpfs/exfel/d/proc/MID/202301/p003493/r0022 --karabo-id MID_DET_AGIPD1M-1 --run 22
2023-06-07 12:15:59,918 - root - INFO - [webservice.py:517] Transfer complete: proposal 003493, runs ['22']
2023-06-07 12:15:49,810 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (13/300)
2023-06-07 12:15:39,713 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (12/300)
2023-06-07 12:15:29,624 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (11/300)
2023-06-07 12:15:19,519 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (10/300)
2023-06-07 12:15:09,416 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (9/300)
2023-06-07 12:14:59,323 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (8/300)
2023-06-07 12:14:49,225 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (7/300)
2023-06-07 12:14:39,121 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (6/300)
2023-06-07 12:14:29,015 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (5/300)
2023-06-07 12:14:18,917 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (4/300)
2023-06-07 12:14:08,814 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (3/300)
2023-06-07 12:13:58,723 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (2/300)
2023-06-07 12:13:48,623 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (1/300)
2023-06-07 12:13:38,506 - root - INFO - [webservice.py:471] Proposal 003493 run 22 not migrated yet. Will try again (0/300)
Allocated jobs are in pending state¶
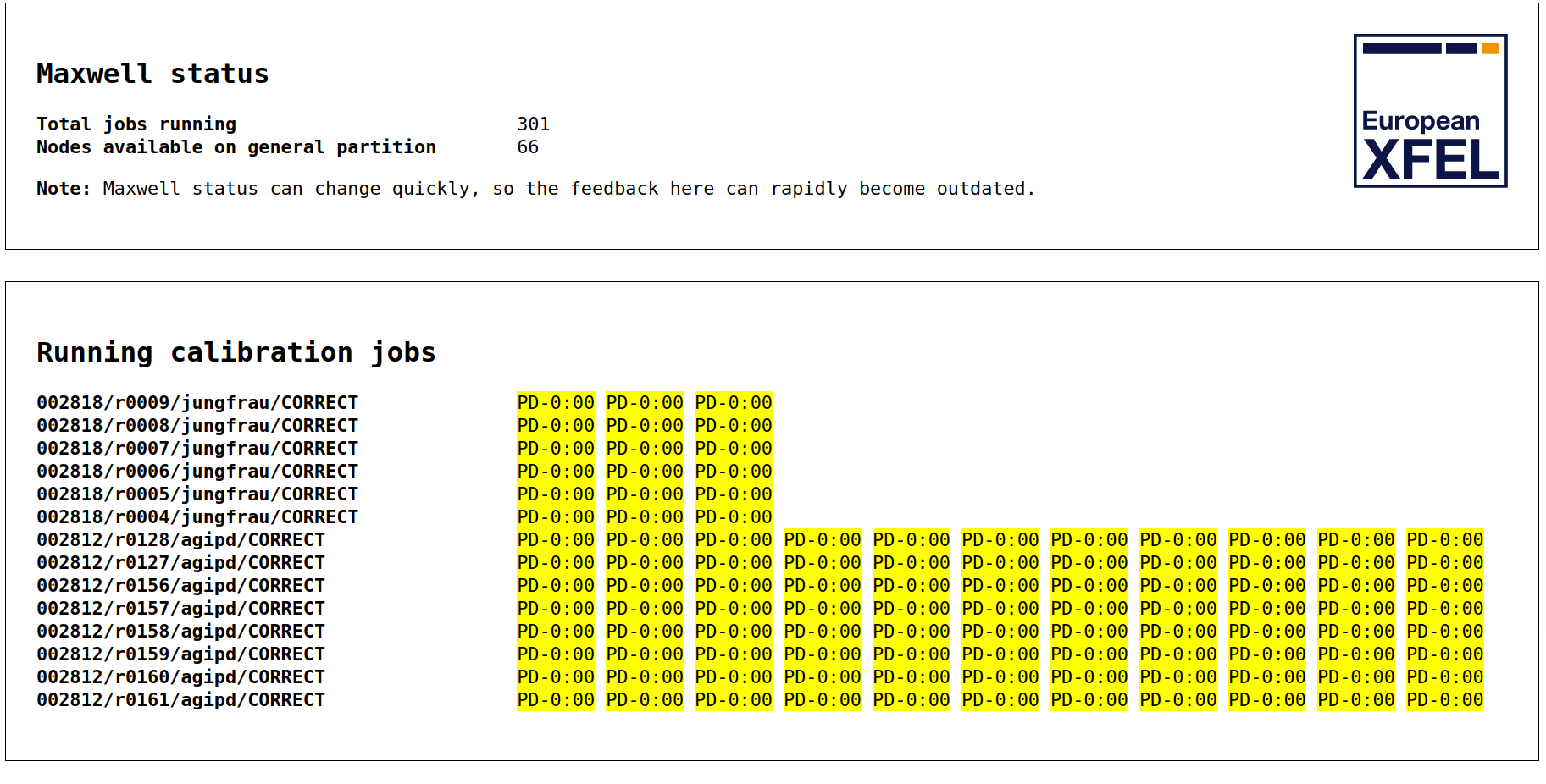
There are two partitions used by the offline calibration for Active proposals. In these partitions xcal has a high priority, hence if all nodes are occupied by different users, xcal would be able to take over the node.
This helps in avoiding the issue of not finding resources during user experiments to run dark processing or corrections. However in some cases it would be possible to get a call about PENDING calibration jobs for too long.
-
One reason would be that the
upex-middle(orupex-highfor darks), which is used for offline correction has all resources occupied by other calibration jobs. This can happen if multiple run corrections were requested for anACTIVEproposal, leading to the delay of another runs from another or same instrument. In case it is another instrument DOC will need to coordinate with both instruments and one solution would be to stop the corrections acquiring all resources if they aren't urgent compared to corrections for another instrument. -
Another reason can be that neither
upex-middlenorupex-highare used for the triggered calibrations. This can be because the runs to be calibrated doesn't belong to anACTIVEproposal. Either because the proposal has finished it'sACTIVEtime window, or data was acquired for this proposal before the expected duration when the proposal should start to beACTIVE. Check calibration partitions for more details.
Correction¶
Correction is taking longer than expected (I/O delay)¶
In case the correction was properly started from myMDC and related jobs are not pending for a long time but rather are processing for longer than expected i.e. in reference to other runs previously corrected in the same proposal. One reason could be is that the data for this run was moved from fast access gpfs to dCache. This movement is expected for proposals after a time window for finished proposals to leave space for new data and active proposals.
Data in dCache has a longer I/O time and for data with many sequence files, data processing can be affected.
To check if the data is on dCache, myMDC can be used.

This image show that the runs are on gpfs and dCache, there can be other proposals which have some or all runs only on dCache.
Correction failed no constants found¶
For most of the detectors in case the offset dark constant was not retrieved, the correction will not go through.